
چرا کاخ سفید میخواهد هکرها نقاط ضعف هوش مصنوعی را پیدا کنند؟

بی بی سی فارسی
- فیلیپا وین
- گزارشگر فناوری بیبیسی
منبع تصویر، Getty Images
توضیح تصویر،لاس وگاس میزبان همایش «دف کان ۳۱» است؛ بزرگترین کنفرانس هکرها در جهان
چه میشود اگر هزاران هکر در یک شهر جمع شوند، تنها با این هدف که هوش مصنوعی را فریب دهند و نقاط ضعف آن را پیدا کنند؟ این سوالی است که کاخ سفید به دنبال جواب آن است.
سی و یکمین دوره «دِف کان»، بزرگترین گردهمآیی سالانه هکرها، در شهر لاس وگاس در حال برگزاری است و برای اولین بار شرکتهای بزرگ فناوری، سیستمهای قدرتمند خود را در معرض آزمایش قرار میدهند.
در این میان مدلهای زبانی بزرگ و چتباتها یا باتهای مکالمه مشهوری مانند اوپنایآی چتجیتیپی و بارد گوگل در مرکز توجه هستند.
دکتر رامن چودری، مدیر عامل شرکت «هوش بشری» و پژوهشگر «هوش مصنوعی مسئولیتپذیر» در هاروارد یکی از برگزارکنندگان این همایش است.
خانم چودری به بیبیسی گفت که آنها مسابقهای برای «تشخیص مشکلات سیستمهای هوش مصنوعی» و «ارزیابی مستقل» آنها طراحی کردهاند.
Skip مطالب پیشنهادی and continue readingمطالب پیشنهادی- در بحبوحه اعتصابات هالیوود، نتفلیکس آگهی استخدام برای متخصص هوش مصنوعی گذاشت
- هوش مصنوعی چیست؟ آیا خطرناک است؟
- چرا ایمنسازی هوش مصنوعی آنقدرها هم که فکر میکنید آسان نیست
- محدودیتهای اینترنتی و فیلترینگ، بلای جان کسب و کار اینترنتی ایران
End of مطالب پیشنهادی
او میگوید این رویداد فضای امنی را برای شرکتهای بزرگ ایجاد میکند تا درباره مشکلات خود و شیوه حل و فصل آن صحبت کنند.
در این اجلاس از شرکتهای متا، گوگل، اوپنایآی، انتروپیک، کوهیر، انویدیا و استبیلیتی دعوت شده تا مدلهای خود را در معرض هک شدن قرار دهند تا نقایص این سیستمها شناسایی شود.
به گفته دکتر چودری شرکتها میدانند که در جریان کار ممکن است اشتباهات زیادی رخ دهد و این مسابقه راهی است برای دریافتن این که اگر گروهی از هکرهای مصمم در برابر مدلهای زبانی این شرکتها قرار بگیرند، چه اتفاقی ممکن است بیفتد.
مسابقه چگونه برگزار میشود؟
برگزارکنندگان برآورد میکنند که طی دو روز و نیم، سههزار نفر -هر کدام به تنهایی و در بازه زمانی ۵۰ دقیقهای که به آنها داده میشود- روی یکی از ۱۵۸ لپتاپی که آنجاست کار میکنند تا بتوانند نقاط ضعف هشت مدل زبانی بزرگ را پیدا کنند.
شرکتکنندگان در حین مسابقه نمیدانند که دارند با مدل زبانی کدام شرکت کار میکنند، هر چند که کارآزمودهها ممکن است بتوانند حدس بزنند که با چه سیستمی طرف هستند. پیدا کردن موفقیتآمیز هر نقطه ضعفی در سیستم امتیاز دارد و کسی که بیشترین امتیاز را بگیرد برنده مسابقه خواهد شد.
جایزه این رقابت یک کیت قدرتمند کامپیوتری و یک واحد پردازنده گرافیکی است. اما شاید از آن مهمتر به گفته دکتر چودری، «حق کل کل و خودنمایی» برای برندگان است.
در یکی از مراحل مسابقه از هکرها میخواهند کاری کنند که مدل زبانی درباره یک سیاستمدار یا یک شخصیت مهم دچار توهم و تصور نادرست شود یا از خود اطلاعاتی درباره آن شخص بسازد که واقعیت ندارد.
منبع تصویر، RCHOWDHURY
توضیح تصویر،دکتر رامن چودری یکی از برگزارکنندگان مسابقه هوش مصنوعی است
دکتر سرافینا گلدفرب-تارنت، رئیس ایمنی هوش مصنوعی در شرکت «کوهیر» میگوید هر چند این موضوع روشن است که مدلهای زبانی قادر به تولید اطلاعات مندرآوردی هستند، اما مشخص نیست که این اتفاق تا چه حد رخ میدهد و میزان تکرار آن چقدر است.
او میگوید «ما میدانیم که مدلها دچار توهم اطلاعاتی میشوند، اما مفید خواهد بود اگر بتوانیم آگاهیمان را درباره این که این اتفاق چقدر تکرار میشود، بالا ببریم. هنوز درباره این موضوع اطلاع زیادی نداریم.»
پایداری و پیوستگی مدلها هم قرار است آزمایش شود. به گفته دکتر گلدفرب-تارنت «نگرانیهایی درباره این موضوع وجود دارد که مدلها در برخورد با زبانهای مختلف چگونه کار میکنند».
منبع تصویر، Getty Images
توضیح تصویر،جو بایدن، رئیس جمهور آمریکا در کاخ سفید در شهر واشنگتن، درباره هوش مصنوعی صحبت میکند
برای مثال او میگوید اگر از انواع مدلهای بزرگ زبانی، به انگلیسی بپرسید که چطور میتوان عضو یک سازمان تروریستی شد، آنها پاسخی به شما نخواهند داد، چون یک نوع مکانیسم ایمنی در آنها فعال میشود. اما ممکن است همین سوال را به زبان دیگری از همان مدل بپرسید و او لیستی از گامهای لازم را به شما پیشنهاد کند.
دکتر گلدفرپ-تارنت که آماده کردن مدلهای زبانی شرکت کوهیر برای این رویداد را برعهده داشته، میگوید با وجود توان و قدرتی که این مدلها دارند، اما «لزوما این طور نیست که مدلهای ما آسیبپذیر نباشند، بلکه ما هنوز این نقاط ضعف را پیدا نکردهایم.»
مشکلات کنونی
از پادکست رد شوید و به خواندن ادامه دهیدصفحه ۲در این برنامه با صاحبنظران درباره مسائل سیاسی و اجتماعی روز گفت و گو میکنیم.
پادکست
پایان پادکست
این گردهمآیی با حمایت کاخ سفید برگزار میشود. دولت آمریکا این موضوع را حدود سه ماه پیش اعلام کرد و گفت که «اطلاعات حیاتی درباره تاثیرات این مدلها را به پژوهشگران و عموم مردم اعلام خواهد کرد و این امکان را برای شرکتهای هوش مصنوعی و برنامهنویسان فراهم خواهد کرد که گامهای لازم را برای برطرف کردن نقاط ضعفی که در مدلهای زبانی آنها پیدا میشود، بردارند.»
سرعت و شتاب شرکتها در ساخت این برنامهها و مدلها تا حدی بوده که باعث نگرانی از انتشار و گسترش اطلاعات جعلی، به خصوص پیش از انتخابات ریاست جمهوری سال آینده در آمریکا شده است. ماه گذشته میلادی هفت شرکت بزرگ هوش مصنوعی به صورت داوطلبانه پایبندی خود را به مجموعهای از تدابیر ایمنی اعلام کردند که قرار است میزان ریسک و تهدید فناوریهای پیشرفته را کاهش دهد. با وجود این توافق بر سر پادمانهای قانونی و حقوقی به زمان بیشتری نیاز دارد.
دکتر چاودری میگوید «رقابت در شاخه قانونگذاری همین الان هم در جریان است»، و این رویداد، بیش از آن که تهدیدهای وجودی را پوشش دهد، راهی است برای پررنگ کردن مشکلات کنونی هوش مصنوعی.
او میگوید موضوع این گردهمآیی این نیست که آیا سیستمهای هوش مصنوعی میتوانند یک سلاح هستهای را منفجر کند یا نه، بلکه این است که «آیا در خود آنها آسیب یا انحراف و جهتگیری وجود دارد یا نه».
«مثلا میخواهیم بفهمیم که آیا آنها به ما دروغ میگویند، از خودشان پایتخت جعلی برای یک کشور میسازند، درباره صلاحیت پزشکی و درمانی خودشان دروغ میگویند یا مثلا ممکن است اطلاعاتی درباره سیاست به ما بدهند که کاملا جعلی باشد.»
خواسته دکتر گلدفرب تارنت این است که تمرکز گردهمآیی روی وضع مقرراتی باشد که بتواند مشکلات جاری را از میان بردارد. او از دولتها میخواهد برای قانونگذاری در موضوع هوش مصنوعی وقت بگذارند تا جلو انتشار اخبار جعلی و اطلاعات غلط گرفته شود.
چه اتفاقی خواهد افتاد؟
دکتر چودری میخواهد بداند «چه اتفاقی میافتد اگر ما نقاط ضعفی را در این مدلهای زبانی پیدا کنیم، واکنش شرکتهای فناوری چه خواهد بود؟»
«اگر ما نتوانیم مدلهای ساده یادگیری ماشینی هوش مصنوعی را بدون جهتگیری یا تبعیض بسازیم، در آینده نخواهیم توانست مدلهای پیچیده هوش مصنوعی مولد را بدون وجود چنین مشکلاتی در اختیار داشته باشیم.»
وقتی که مسابقه پیدا کردن نقطه ضعفها به پایان برسد، شرکتهای به اطلاعات جمعآوریشده دسترسی پیدا میکنند و امکان واکنش به نقایصی را خواهند داشت که در جریان این رقابتها پیدا شده است.
پژوهشگران مستقل هم میتوانند برای دسترسی به این دادهها درخواست بدهند و قرار است که نتیجه این رقابتها فوریه سال آینده میلادی منتشر شود.
- فیلیپا وین
- گزارشگر فناوری بیبیسی

منبع تصویر، Getty Images
لاس وگاس میزبان همایش «دف کان ۳۱» است؛ بزرگترین کنفرانس هکرها در جهان
چه میشود اگر هزاران هکر در یک شهر جمع شوند، تنها با این هدف که هوش مصنوعی را فریب دهند و نقاط ضعف آن را پیدا کنند؟ این سوالی است که کاخ سفید به دنبال جواب آن است.
سی و یکمین دوره «دِف کان»، بزرگترین گردهمآیی سالانه هکرها، در شهر لاس وگاس در حال برگزاری است و برای اولین بار شرکتهای بزرگ فناوری، سیستمهای قدرتمند خود را در معرض آزمایش قرار میدهند.
در این میان مدلهای زبانی بزرگ و چتباتها یا باتهای مکالمه مشهوری مانند اوپنایآی چتجیتیپی و بارد گوگل در مرکز توجه هستند.
دکتر رامن چودری، مدیر عامل شرکت «هوش بشری» و پژوهشگر «هوش مصنوعی مسئولیتپذیر» در هاروارد یکی از برگزارکنندگان این همایش است.
خانم چودری به بیبیسی گفت که آنها مسابقهای برای «تشخیص مشکلات سیستمهای هوش مصنوعی» و «ارزیابی مستقل» آنها طراحی کردهاند.
او میگوید این رویداد فضای امنی را برای شرکتهای بزرگ ایجاد میکند تا درباره مشکلات خود و شیوه حل و فصل آن صحبت کنند.
در این اجلاس از شرکتهای متا، گوگل، اوپنایآی، انتروپیک، کوهیر، انویدیا و استبیلیتی دعوت شده تا مدلهای خود را در معرض هک شدن قرار دهند تا نقایص این سیستمها شناسایی شود.
به گفته دکتر چودری شرکتها میدانند که در جریان کار ممکن است اشتباهات زیادی رخ دهد و این مسابقه راهی است برای دریافتن این که اگر گروهی از هکرهای مصمم در برابر مدلهای زبانی این شرکتها قرار بگیرند، چه اتفاقی ممکن است بیفتد.
مسابقه چگونه برگزار میشود؟
برگزارکنندگان برآورد میکنند که طی دو روز و نیم، سههزار نفر -هر کدام به تنهایی و در بازه زمانی ۵۰ دقیقهای که به آنها داده میشود- روی یکی از ۱۵۸ لپتاپی که آنجاست کار میکنند تا بتوانند نقاط ضعف هشت مدل زبانی بزرگ را پیدا کنند.
شرکتکنندگان در حین مسابقه نمیدانند که دارند با مدل زبانی کدام شرکت کار میکنند، هر چند که کارآزمودهها ممکن است بتوانند حدس بزنند که با چه سیستمی طرف هستند. پیدا کردن موفقیتآمیز هر نقطه ضعفی در سیستم امتیاز دارد و کسی که بیشترین امتیاز را بگیرد برنده مسابقه خواهد شد.
جایزه این رقابت یک کیت قدرتمند کامپیوتری و یک واحد پردازنده گرافیکی است. اما شاید از آن مهمتر به گفته دکتر چودری، «حق کل کل و خودنمایی» برای برندگان است.
در یکی از مراحل مسابقه از هکرها میخواهند کاری کنند که مدل زبانی درباره یک سیاستمدار یا یک شخصیت مهم دچار توهم و تصور نادرست شود یا از خود اطلاعاتی درباره آن شخص بسازد که واقعیت ندارد.
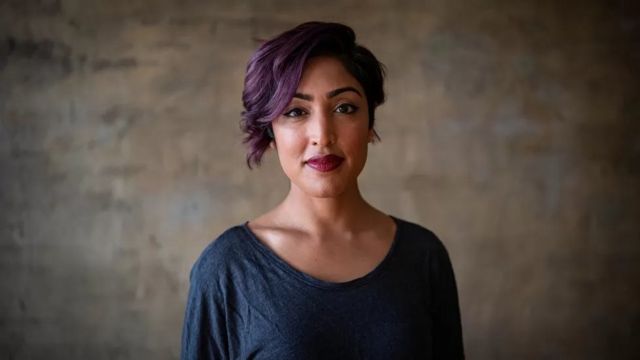
منبع تصویر، RCHOWDHURY
دکتر رامن چودری یکی از برگزارکنندگان مسابقه هوش مصنوعی است
دکتر سرافینا گلدفرب-تارنت، رئیس ایمنی هوش مصنوعی در شرکت «کوهیر» میگوید هر چند این موضوع روشن است که مدلهای زبانی قادر به تولید اطلاعات مندرآوردی هستند، اما مشخص نیست که این اتفاق تا چه حد رخ میدهد و میزان تکرار آن چقدر است.
او میگوید «ما میدانیم که مدلها دچار توهم اطلاعاتی میشوند، اما مفید خواهد بود اگر بتوانیم آگاهیمان را درباره این که این اتفاق چقدر تکرار میشود، بالا ببریم. هنوز درباره این موضوع اطلاع زیادی نداریم.»
پایداری و پیوستگی مدلها هم قرار است آزمایش شود. به گفته دکتر گلدفرب-تارنت «نگرانیهایی درباره این موضوع وجود دارد که مدلها در برخورد با زبانهای مختلف چگونه کار میکنند».

منبع تصویر، Getty Images
جو بایدن، رئیس جمهور آمریکا در کاخ سفید در شهر واشنگتن، درباره هوش مصنوعی صحبت میکند
برای مثال او میگوید اگر از انواع مدلهای بزرگ زبانی، به انگلیسی بپرسید که چطور میتوان عضو یک سازمان تروریستی شد، آنها پاسخی به شما نخواهند داد، چون یک نوع مکانیسم ایمنی در آنها فعال میشود. اما ممکن است همین سوال را به زبان دیگری از همان مدل بپرسید و او لیستی از گامهای لازم را به شما پیشنهاد کند.
دکتر گلدفرپ-تارنت که آماده کردن مدلهای زبانی شرکت کوهیر برای این رویداد را برعهده داشته، میگوید با وجود توان و قدرتی که این مدلها دارند، اما «لزوما این طور نیست که مدلهای ما آسیبپذیر نباشند، بلکه ما هنوز این نقاط ضعف را پیدا نکردهایم.»
مشکلات کنونی

این گردهمآیی با حمایت کاخ سفید برگزار میشود. دولت آمریکا این موضوع را حدود سه ماه پیش اعلام کرد و گفت که «اطلاعات حیاتی درباره تاثیرات این مدلها را به پژوهشگران و عموم مردم اعلام خواهد کرد و این امکان را برای شرکتهای هوش مصنوعی و برنامهنویسان فراهم خواهد کرد که گامهای لازم را برای برطرف کردن نقاط ضعفی که در مدلهای زبانی آنها پیدا میشود، بردارند.»
سرعت و شتاب شرکتها در ساخت این برنامهها و مدلها تا حدی بوده که باعث نگرانی از انتشار و گسترش اطلاعات جعلی، به خصوص پیش از انتخابات ریاست جمهوری سال آینده در آمریکا شده است. ماه گذشته میلادی هفت شرکت بزرگ هوش مصنوعی به صورت داوطلبانه پایبندی خود را به مجموعهای از تدابیر ایمنی اعلام کردند که قرار است میزان ریسک و تهدید فناوریهای پیشرفته را کاهش دهد. با وجود این توافق بر سر پادمانهای قانونی و حقوقی به زمان بیشتری نیاز دارد.
دکتر چاودری میگوید «رقابت در شاخه قانونگذاری همین الان هم در جریان است»، و این رویداد، بیش از آن که تهدیدهای وجودی را پوشش دهد، راهی است برای پررنگ کردن مشکلات کنونی هوش مصنوعی.
او میگوید موضوع این گردهمآیی این نیست که آیا سیستمهای هوش مصنوعی میتوانند یک سلاح هستهای را منفجر کند یا نه، بلکه این است که «آیا در خود آنها آسیب یا انحراف و جهتگیری وجود دارد یا نه».
«مثلا میخواهیم بفهمیم که آیا آنها به ما دروغ میگویند، از خودشان پایتخت جعلی برای یک کشور میسازند، درباره صلاحیت پزشکی و درمانی خودشان دروغ میگویند یا مثلا ممکن است اطلاعاتی درباره سیاست به ما بدهند که کاملا جعلی باشد.»
خواسته دکتر گلدفرب تارنت این است که تمرکز گردهمآیی روی وضع مقرراتی باشد که بتواند مشکلات جاری را از میان بردارد. او از دولتها میخواهد برای قانونگذاری در موضوع هوش مصنوعی وقت بگذارند تا جلو انتشار اخبار جعلی و اطلاعات غلط گرفته شود.
چه اتفاقی خواهد افتاد؟
دکتر چودری میخواهد بداند «چه اتفاقی میافتد اگر ما نقاط ضعفی را در این مدلهای زبانی پیدا کنیم، واکنش شرکتهای فناوری چه خواهد بود؟»
«اگر ما نتوانیم مدلهای ساده یادگیری ماشینی هوش مصنوعی را بدون جهتگیری یا تبعیض بسازیم، در آینده نخواهیم توانست مدلهای پیچیده هوش مصنوعی مولد را بدون وجود چنین مشکلاتی در اختیار داشته باشیم.»
وقتی که مسابقه پیدا کردن نقطه ضعفها به پایان برسد، شرکتهای به اطلاعات جمعآوریشده دسترسی پیدا میکنند و امکان واکنش به نقایصی را خواهند داشت که در جریان این رقابتها پیدا شده است.
پژوهشگران مستقل هم میتوانند برای دسترسی به این دادهها درخواست بدهند و قرار است که نتیجه این رقابتها فوریه سال آینده میلادی منتشر شود.
- فیلیپا وین
- گزارشگر فناوری بیبیسی
منبع تصویر، Getty Images
لاس وگاس میزبان همایش «دف کان ۳۱» است؛ بزرگترین کنفرانس هکرها در جهان
چه میشود اگر هزاران هکر در یک شهر جمع شوند، تنها با این هدف که هوش مصنوعی را فریب دهند و نقاط ضعف آن را پیدا کنند؟ این سوالی است که کاخ سفید به دنبال جواب آن است.
سی و یکمین دوره «دِف کان»، بزرگترین گردهمآیی سالانه هکرها، در شهر لاس وگاس در حال برگزاری است و برای اولین بار شرکتهای بزرگ فناوری، سیستمهای قدرتمند خود را در معرض آزمایش قرار میدهند.
در این میان مدلهای زبانی بزرگ و چتباتها یا باتهای مکالمه مشهوری مانند اوپنایآی چتجیتیپی و بارد گوگل در مرکز توجه هستند.
دکتر رامن چودری، مدیر عامل شرکت «هوش بشری» و پژوهشگر «هوش مصنوعی مسئولیتپذیر» در هاروارد یکی از برگزارکنندگان این همایش است.
خانم چودری به بیبیسی گفت که آنها مسابقهای برای «تشخیص مشکلات سیستمهای هوش مصنوعی» و «ارزیابی مستقل» آنها طراحی کردهاند.
او میگوید این رویداد فضای امنی را برای شرکتهای بزرگ ایجاد میکند تا درباره مشکلات خود و شیوه حل و فصل آن صحبت کنند.
در این اجلاس از شرکتهای متا، گوگل، اوپنایآی، انتروپیک، کوهیر، انویدیا و استبیلیتی دعوت شده تا مدلهای خود را در معرض هک شدن قرار دهند تا نقایص این سیستمها شناسایی شود.
به گفته دکتر چودری شرکتها میدانند که در جریان کار ممکن است اشتباهات زیادی رخ دهد و این مسابقه راهی است برای دریافتن این که اگر گروهی از هکرهای مصمم در برابر مدلهای زبانی این شرکتها قرار بگیرند، چه اتفاقی ممکن است بیفتد.
مسابقه چگونه برگزار میشود؟
برگزارکنندگان برآورد میکنند که طی دو روز و نیم، سههزار نفر -هر کدام به تنهایی و در بازه زمانی ۵۰ دقیقهای که به آنها داده میشود- روی یکی از ۱۵۸ لپتاپی که آنجاست کار میکنند تا بتوانند نقاط ضعف هشت مدل زبانی بزرگ را پیدا کنند.
شرکتکنندگان در حین مسابقه نمیدانند که دارند با مدل زبانی کدام شرکت کار میکنند، هر چند که کارآزمودهها ممکن است بتوانند حدس بزنند که با چه سیستمی طرف هستند. پیدا کردن موفقیتآمیز هر نقطه ضعفی در سیستم امتیاز دارد و کسی که بیشترین امتیاز را بگیرد برنده مسابقه خواهد شد.
جایزه این رقابت یک کیت قدرتمند کامپیوتری و یک واحد پردازنده گرافیکی است. اما شاید از آن مهمتر به گفته دکتر چودری، «حق کل کل و خودنمایی» برای برندگان است.
در یکی از مراحل مسابقه از هکرها میخواهند کاری کنند که مدل زبانی درباره یک سیاستمدار یا یک شخصیت مهم دچار توهم و تصور نادرست شود یا از خود اطلاعاتی درباره آن شخص بسازد که واقعیت ندارد.
منبع تصویر، RCHOWDHURY
دکتر رامن چودری یکی از برگزارکنندگان مسابقه هوش مصنوعی است
دکتر سرافینا گلدفرب-تارنت، رئیس ایمنی هوش مصنوعی در شرکت «کوهیر» میگوید هر چند این موضوع روشن است که مدلهای زبانی قادر به تولید اطلاعات مندرآوردی هستند، اما مشخص نیست که این اتفاق تا چه حد رخ میدهد و میزان تکرار آن چقدر است.
او میگوید «ما میدانیم که مدلها دچار توهم اطلاعاتی میشوند، اما مفید خواهد بود اگر بتوانیم آگاهیمان را درباره این که این اتفاق چقدر تکرار میشود، بالا ببریم. هنوز درباره این موضوع اطلاع زیادی نداریم.»
پایداری و پیوستگی مدلها هم قرار است آزمایش شود. به گفته دکتر گلدفرب-تارنت «نگرانیهایی درباره این موضوع وجود دارد که مدلها در برخورد با زبانهای مختلف چگونه کار میکنند».
منبع تصویر، Getty Images
جو بایدن، رئیس جمهور آمریکا در کاخ سفید در شهر واشنگتن، درباره هوش مصنوعی صحبت میکند
برای مثال او میگوید اگر از انواع مدلهای بزرگ زبانی، به انگلیسی بپرسید که چطور میتوان عضو یک سازمان تروریستی شد، آنها پاسخی به شما نخواهند داد، چون یک نوع مکانیسم ایمنی در آنها فعال میشود. اما ممکن است همین سوال را به زبان دیگری از همان مدل بپرسید و او لیستی از گامهای لازم را به شما پیشنهاد کند.
دکتر گلدفرپ-تارنت که آماده کردن مدلهای زبانی شرکت کوهیر برای این رویداد را برعهده داشته، میگوید با وجود توان و قدرتی که این مدلها دارند، اما «لزوما این طور نیست که مدلهای ما آسیبپذیر نباشند، بلکه ما هنوز این نقاط ضعف را پیدا نکردهایم.»
مشکلات کنونی
این گردهمآیی با حمایت کاخ سفید برگزار میشود. دولت آمریکا این موضوع را حدود سه ماه پیش اعلام کرد و گفت که «اطلاعات حیاتی درباره تاثیرات این مدلها را به پژوهشگران و عموم مردم اعلام خواهد کرد و این امکان را برای شرکتهای هوش مصنوعی و برنامهنویسان فراهم خواهد کرد که گامهای لازم را برای برطرف کردن نقاط ضعفی که در مدلهای زبانی آنها پیدا میشود، بردارند.»
سرعت و شتاب شرکتها در ساخت این برنامهها و مدلها تا حدی بوده که باعث نگرانی از انتشار و گسترش اطلاعات جعلی، به خصوص پیش از انتخابات ریاست جمهوری سال آینده در آمریکا شده است. ماه گذشته میلادی هفت شرکت بزرگ هوش مصنوعی به صورت داوطلبانه پایبندی خود را به مجموعهای از تدابیر ایمنی اعلام کردند که قرار است میزان ریسک و تهدید فناوریهای پیشرفته را کاهش دهد. با وجود این توافق بر سر پادمانهای قانونی و حقوقی به زمان بیشتری نیاز دارد.
دکتر چاودری میگوید «رقابت در شاخه قانونگذاری همین الان هم در جریان است»، و این رویداد، بیش از آن که تهدیدهای وجودی را پوشش دهد، راهی است برای پررنگ کردن مشکلات کنونی هوش مصنوعی.
او میگوید موضوع این گردهمآیی این نیست که آیا سیستمهای هوش مصنوعی میتوانند یک سلاح هستهای را منفجر کند یا نه، بلکه این است که «آیا در خود آنها آسیب یا انحراف و جهتگیری وجود دارد یا نه».
«مثلا میخواهیم بفهمیم که آیا آنها به ما دروغ میگویند، از خودشان پایتخت جعلی برای یک کشور میسازند، درباره صلاحیت پزشکی و درمانی خودشان دروغ میگویند یا مثلا ممکن است اطلاعاتی درباره سیاست به ما بدهند که کاملا جعلی باشد.»
خواسته دکتر گلدفرب تارنت این است که تمرکز گردهمآیی روی وضع مقرراتی باشد که بتواند مشکلات جاری را از میان بردارد. او از دولتها میخواهد برای قانونگذاری در موضوع هوش مصنوعی وقت بگذارند تا جلو انتشار اخبار جعلی و اطلاعات غلط گرفته شود.
چه اتفاقی خواهد افتاد؟
دکتر چودری میخواهد بداند «چه اتفاقی میافتد اگر ما نقاط ضعفی را در این مدلهای زبانی پیدا کنیم، واکنش شرکتهای فناوری چه خواهد بود؟»
«اگر ما نتوانیم مدلهای ساده یادگیری ماشینی هوش مصنوعی را بدون جهتگیری یا تبعیض بسازیم، در آینده نخواهیم توانست مدلهای پیچیده هوش مصنوعی مولد را بدون وجود چنین مشکلاتی در اختیار داشته باشیم.»
وقتی که مسابقه پیدا کردن نقطه ضعفها به پایان برسد، شرکتهای به اطلاعات جمعآوریشده دسترسی پیدا میکنند و امکان واکنش به نقایصی را خواهند داشت که در جریان این رقابتها پیدا شده است.
پژوهشگران مستقل هم میتوانند برای دسترسی به این دادهها درخواست بدهند و قرار است که نتیجه این رقابتها فوریه سال آینده میلادی منتشر شود.
منبع خبر: بی بی سی فارسی ![]()
اخبار مرتبط: چرا کاخ سفید میخواهد هکرها نقاط ضعف هوش مصنوعی را پیدا کنند؟